Dit artikel is geschreven op verzoek van de High Giftedness Expertise Group (HGEG),
als onderdeel van de online kennisbank die zij op zijn aan het zetten.
“Het maakt niet uit welke intelligentietest je gebruikt. Ze meten allemaal hetzelfde, toch?”
Intelligentieonderzoek bij (zeer) hoogbegaafden
Waarom een aparte intelligentietest geen luxe maar noodzaak is
Waarom zou je eigenlijk wíllen weten of jij (of je kind of cliënt) (zeer) hoogbegaafd bent (is)? Voor sommige mensen is signaleren genoeg: herkenning geeft taal, opluchting en handvatten. Maar soms staat er meer op het spel. Denk aan toegang tot passend onderwijs, versnellen of verrijken, een werkcontext die beter past, of het doorbreken van jarenlange misinterpretaties (“je bent lui”, “je stelt je aan”, “je bent slim maar haalt het er niet uit”). Een betrouwbare intelligentiemeting kan dan helpen om ruis van realiteit te scheiden: niet om een etiket te plakken, maar om een stevig ankerpunt te hebben voor keuzes en begeleiding.
Tegelijk is intelligentie in kaart brengen bij (zeer) hoogbegaafden een vak apart. Veel gangbare testen zijn uitstekend rond het gemiddelde, maar worden minder precies aan de randen van het scorebereik. Bij hoge scores spelen bovendien praktische en interpretatieve valkuilen: tijdsdruk, subtestplafonds, te snelle afbreekregels, taal- en cultuurinvloeden, én de neiging om kleine verschillen in profielscores te zwaar te wegen. Dat kan leiden tot onderschatting, maar ook tot het ‘vinden’ van problemen die er in het dagelijks functioneren helemaal niet zijn.
In dit artikel lees je (1) waarom kenmerkenlijstjes en modellen nuttig zijn voor herkenning, maar niet geschikt om hoogbegaafdheid vast te stellen, (2) waarom reguliere testen beperkingen hebben bij hoge scores, en (3) welke uitgangspunten en keuzes het verschil maken als je wél zo betrouwbaar mogelijk wilt meten—bijvoorbeeld met instrumenten die beter differentiëren aan de bovenkant en scoringmethoden gebruiken die meer informatie uit antwoordpatronen halen.
Hoogbegaafdheid: model vs definitie
Veel mensen herkennen zichzelf of hun kinderen in lijstjes met kenmerken, zoals de zijnskenmerken van Prof. Tessa Kieboom of de overexcitabilities van Dabrowski. Deze breed circulerende kenmerkenlijstjes volgen uit verschillende modellen over hoogbegaafdheid.
Een model is een vereenvoudigde weergave van de werkelijkheid, met als doel te begrijpen hoe verschillende onderdelen met elkaar interacteren.
Modellen over hoogbegaafdheid ontstaan meestal vanuit de zorg- of onderwijspraktijk, nadat bepaalde kenmerken en gedragingen vaak geobserveerd zijn bij de hoogbegaafden waarmee professionals in aanraking komen. Ze zijn waardevol voor het beter begrijpen wat hoogbegaafdheid voor gevolgen kan hebben bij de interactie met anderen en/of met de omgeving, en kunnen dus helpen bij het beter begrijpen van jezelf, en bij het signaleren van mogelijke kenmerken van en gedragingen bij hoogbegaafdheid.
Wat echter vaak vergeten wordt, is dat aan de basis van veel modellen vooral observaties bij een selecte groep hoogbegaafden staan. Een model dat gemaakt wordt door een (groep) zorgprofessional(s) na het observeren van kenmerken en gedragingen bij veel hoogbegaafden die bij hen in de praktijk komen, is bijvoorbeeld gebaseerd op de groep ‘hoogbegaafden die tegen problemen aanlopen waarvoor onderzoek, begeleiding en/of behandeling nodig is’.
Of de in het model verwerkte kenmerken ook gelden voor hoogbegaafden zonder problemen is vaak niet goed onderzocht. Net als of de in het model genoemde kenmerken misschien ook gelden voor mensen die helemaal niet hoogbegaafd zijn. Waar je een model (en de daarvan afgeleide lijstjes met kenmerken) daarom niet voor kunt gebruiken, is om te bepalen of je daadwerkelijk hoogbegaafd bent.
Een definitie beschrijft zo nauwkeurig mogelijk wie/wat wel/niet tot de doelgroep behoort. Volledige consensus over de definitie van hoogbegaafdheid is er helaas niet, maar vrijwel iedereen is het erover eens dat in de definitie van hoogbegaafdheid in elk geval een zeer hoge intelligentie voorkomt. Intelligentie is het vermogen om te leren, te begrijpen, abstract te denken en problemen op te lossen. Hoogbegaafden doen dat significant beter dan gemiddeld. En het fijne van intelligentie is dat het goed meetbaar is, en vrij stabiel.
Voor hoogbegaafdheid wordt in de definitie een IQ van minimaal twee standaarddeviaties boven het gemiddelde aangehouden. In de meeste moderne intelligentietesten, die een schaal met een gemiddelde van 100 en een standaarddeviatie van 15 hanteren, betekent dat een IQ van 130 of hoger. Voor ‘zeer hoogbegaafd’ geldt een IQ van 145 als ondergrens.
Wil je dus echt meer zekerheid over of je hoogbegaafd bent of niet? Of heb je behoefte aan meer contact met ontwikkelingsgelijken en wil je daarom lid worden van internationale verenigingen als Mensa (IQ op of boven het 98ste percentiel) of Triple Nine (IQ op of boven het 99,9de percentiel)? Dan is een betrouwbare en goed genormeerde intelligentietest de volgende stap.
Moeilijkheden bij het testen van (vermoedelijk) hoogbegaafden
Een intelligentietest bestaat uit allerlei cognitieve taken waarmee iemands functioneren in kaart gebracht kan worden.
Bij volwassenen is intelligentieonderzoek (vaak online of in groepsverband) soms onderdeel van een assessment tijdens een sollicitatieprocedure of loopbaantraject. De scores kunnen dan een indicatie geven van het soort werkzaamheden dat iemand zou kunnen verrichten en hoeveel instructie en/of begeleiding daarvoor nodig is, maar ook van het niveau opleiding dat iemand kan en mag gaan volgen.
Het doel van intelligentieonderzoek bij kinderen en jongeren is vaak om te beoordelen of intelligentie aan de basis kan liggen van leer- of gedragsproblematiek, en zo ja, op welke vaardigheden iemand relatief het meeste achterblijft (of juist mee zou kunnen compenseren). Zo kan een zwak ontwikkeld werkgeheugen ervoor zorgen dat een kind minder informatie vast kan houden, en daardoor de draad kwijtraakt bij het maken van rekensommen waarvoor meerdere stapjes nodig zijn.
De meeste moderne, goed genormeerde intelligentietesten (zoals de WISC-V of de WAIS-IV) zijn hiervoor over het algemeen goed bruikbaar. Bij het testen van vermoedelijk hoogbegaafde kinderen en volwassenen lopen onderzoekers in de praktijk echter tegen een aantal beperkingen aan.
De belangrijkste beperkingen
Tijdsdruk
Bij een deel van de subtesten in veelgebruikte intelligentietesten is sprake van een maximaal toegestane tijd per opgave. Niet alleen bij onderdelen die specifiek bedoeld zijn om reactie- of verwerkingssnelheid te meten, maar ook bij onderdelen waarmee gemeten wordt of iemand in staat is om logisch na te denken. Dit lijkt voor de hand liggend, want mensen die slimmer zijn denken meestal ook sneller. Echter:
Sommige mensen functioneren beter wanneer er sprake is van tijdsdruk, terwijl anderen er juist stress van krijgen en daardoor niet meer goed kunnen presteren.
Te veel tijdsdruk zorgt ervoor dat mensen die zorgvuldig nadenken en hun antwoorden graag even dubbelchecken, relatief lager scoren. Niet omdat ze minder intelligent zijn, maar omdat goede antwoorden die buiten de tijd gegeven worden minder punten opleveren, of zelfs helemaal niet meetellen.
Dit veroorzaakt ruis in de intelligentiemeting. In veel landen wordt daarom geadviseerd om tijdsdruk te beperken bij het identificeren van hoogbegaafde kinderen [NAGC, 2018] omdat blijkt dat dit belemmerend kan werken [Silverman, 2018].
Taal en aangeleerde kennis
Taal- en kennisvragen zijn vaak onderdeel van een intelligentietest. Op zich is dat logisch, want met een hoge intelligentie kun je relatief makkelijker leren dan gemiddeld. Dat uit zich over het algemeen ook in een grotere woordenschat, een hogere taalvaardigheid en een grotere algemene kennis. Er zijn echter ook nadelen aan het gebruik van taal- en kennisvragen in een intelligentietest:
Antwoordmodellen komen soms niet overeen met de antwoorden die hoogbegaafden geven: het is voor een tester in dat geval lastig om te beoordelen of een vraag goed of fout beantwoord is. Als de ene tester daardoor een bepaald antwoord wel goed beoordeelt en een andere tester niet, zijn scoreverschillen niet meer het gevolg van een verschil in intelligentie maar van een verschil in beoordeling door de tester (zoals ook bij jurysporten als kunstschaatsen de rangschikking deels beïnvloed kan worden door wie er in de jury zit).
Taal- en kennisvragen zorgen ervoor dat de omgeving waarin iemand is opgegroeid en de ervaringen die iemand heeft opgedaan door de mogelijkheden (zoals opleiding en financiële middelen) die iemand heeft gehad veel invloed hebben op de scores. Dit kan zowel over- als onderschatting tot gevolg hebben. Deze effecten zijn het grootst bij jonge kinderen, maar zijn er zeker ook bij volwassenen.
Onderzoeken naar kinderen met ASS laten zien dat intelligentietesten met een verbaal deel de intelligentie van deze kinderen flink kunnen onderschatten, terwijl de prestatie van kinderen zonder ASS vergelijkbaar is voor intelligentietesten met en zonder een verbaal deel [Nader et al., 2016, Grondhuis et al., 2018]
Meerdere antwoorden mogelijk
Ambiguïteit in de opgaven en/of antwoordmogelijkheden. Iemand die sneller en meer verbanden ziet, kan soms wel zes verschillende redenen bedenken waarom een koe en een varken tot dezelfde categorie behoren, maar ook waarom dat niet zo is. In dat geval zijn er op een vraag meerdere antwoorden mogelijk, terwijl er volgens het antwoordmodel echt maar één juist antwoord is.
Niveaudiscrepantie / te moeilijk denken
Als er een plaatje getoond wordt van een appelboom waarin twee appels zichtbaar zijn, en de vraag is “Hoeveel appels hangen er in deze boom?”, is het doel van zo’n vraag waarschijnlijk om te achterhalen of een kind weet wat een appel is, en of het al tot twee kan tellen. Een slim kind dat van te voren misschien van haar of zijn ouders gehoord heeft dat het die dag allerlei moeilijke puzzeltjes mag gaan maken zal misschien denken “Het antwoord zal vast niet twee zijn, want dat is veel te makkelijk. Misschien hangen er aan de andere kant van de boom ook wel wat appels…” en daarom “Vier” antwoorden. Of zeggen dat hij of zij het antwoord niet weet, want wie zegt dat er aan elke kant van de boom evenveel appels hangen?
Als zoiets aan het begin van een subtest een paar keer gebeurt, kan het zijn dat de subtest volgens de afbreekregels al moet worden afgebroken voordat het kind bij de opgaven aankomt die beter passen bij zijn eigen denkniveau. Dat kan ervoor zorgen dat scores (veel) lager uitvallen dan de werkelijke intelligentie van een kind.
Vanwege het gebruik van somscores, waarbij de ruwe score alleen gebaseerd is op het aantal goede antwoorden, tellen dit soort fouten aan het begin van de test even hard mee als fouten op te moeilijke vragen aan het eind. Ook als de afbreekregel niet te vroeg bereikt wordt, kunnen te makkelijke vragen aan het begin er zo voor zorgen dat de scores lager uitvallen dan de werkelijke intelligentie van een kind.
Waarom is een speciale test voor hoogbegaafden nodig?
Een deel van bovenstaande moeilijkheden, die te maken hebben met het soms moeilijker testbaar zijn van hoogbegaafden, is algemeen bekend en in de praktijk voor een deel nog wel op te vangen. Bijvoorbeeld door een goede klik met de tester, een bewuste keuze in het soort test (bijvoorbeeld een taalarme test zoals de SON-R wanneer iemand de Nederlandse taal nog niet goed beheerst of er vermoedelijk sprake is van ASS), doorvragen (waar en hoe het afnameprotocol dat toestaat) wanneer een antwoord uitblijft of onduidelijk is, en goede verslaglegging met praktische handvatten (waardoor de nadruk minder op de scores komt te liggen, en meer op wat iemand nodig heeft om beter te kunnen functioneren).
Als het gaat om betrouwbaar onderscheid kunnen maken tussen een IQ van bijvoorbeeld 120, 135 of 150 spelen echter ook de moeilijkheidsgraad en de wijze van normeren een belangrijke rol.
Veelgebruikte reguliere intelligentietesten meten heel betrouwbaar rondom het gemiddelde, maar voor het maken van een betrouwbaar onderscheid tussen een hoge en een zeer hoge intelligentie (en dus voor het beoordelen of er sprake is van hoogbegaafdheid, en zo ja in welke mate) zijn ze veel minder geschikt. Bij de meeste testen is het betrouwbare scorebereik namelijk een stuk kleiner dan het scorebereik dat in de productinformatie genoemd wordt. En niet iedereen is zich daarvan bewust.
Te weinig moeilijke vragen
Het eerste probleem bij metingen aan de bovenkant van het scorebereik is dat bij de verdeling van makkelijke en moeilijke vragen het zwaartepunt vaak onder of rond het gemiddelde (IQ 100) ligt.
Zo wordt voor de leeftijdsgroep 30 t/m 34 jaar in de WAIS-IV (afhankelijk van de subtest) ongeveer 60 tot 80% van de opgaven gebruikt voor de onderste helft van het scorebereik (IQ 40-100). Ditzelfde geldt voor de meeste andere individuele intelligentietesten, en ook voor klassikale leerpotentieel-toetsen als de NSCCT. Dat is op zich heel logisch, omdat intelligentietesten nu nog vaak gebruikt worden om te beoordelen of er sprake is van een lage intelligentie. En leerpotentieel-toetsen op school zijn voornamelijk bedoeld om te helpen inschatten welk type vervolgonderwijs het meest passend zou zijn, en daarvoor hoeft er niet verder gedifferentieerd te worden dan het 80ste percentiel: ongeveer 20% van de leerlingen stroomt uit op VWO niveau en moeilijker dan dat wordt het op de middelbare school in Nederland niet.
Wil je echter weten of er sprake is van een zeer hoge intelligentie? Dat kom je hierdoor in de bovenste helft van het scorebereik opgaven tekort.
Met de WAIS-IV subtest Matrix Redeneren (MR), die 26 items bevat, wordt met de eerste 21 opgaven alleen de onderste helft van het scorebereik gemeten: tot en met een geschaalde score van 10 (op de gebruikte subtestscore-schaal van gem 10 SD 3 is dat precies gemiddeld). Er blijven dan nog maar 5 opgaven over om te differentiëren van een geschaalde score van 11 tot en met 16 (de maximaal haalbare geschaalde score voor een 30-jarige op deze subtest).
Behalve dat het saai en/of frustrerend kan zijn om eerst 20 veel te makkelijke opgaven te moeten maken voordat het een beetje interessant wordt, betekent dit ook dat er met deze subtest aan de bovenkant van het scorebereik minder precies (en minder ver) kan worden gedifferentieerd dan aan de onderkant.
Ook het feit dat de ruwe score bij deze subtest een somscore is (1 punt per goed antwoord, waarmee geen onderscheid gemaakt wordt tussen makkelijke en moeilijke opgaven), zorgt ervoor dat differentiëren boven een IQ van 130 eigenlijk niet meer goed mogelijk is. Begrijp je alle MR opgaven goed, maar maak je ergens onderweg een slordigheidsfoutje? Dan zakt je geschaalde score voor deze subtest meteen terug van 16 naar 14.
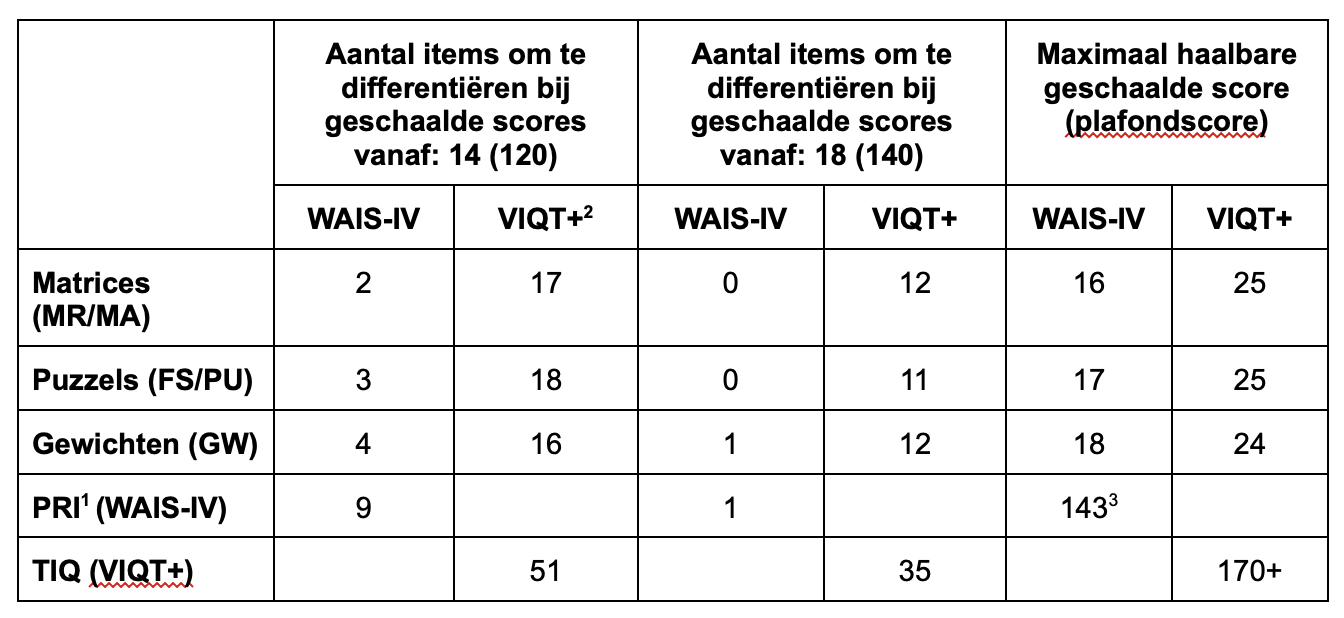
In de tabel hieronder kun je zien hoe de meest op elkaar lijkende subtesten van de WAIS-IV en de VIQT+ zich tot elkaar verhouden voor wat betreft het aantal opgaven waarmee een hoog tot zeer hoog IQ kan worden gemeten bij een 30-jarige.
| Aantal items om te differentiëren bij geschaalde scores vanaf: 14 (120) | Aantal items om te differentiëren bij geschaalde scores vanaf: 18 (140) | Maximaal haalbare geschaalde score (plafondscore) |
||||
| WAIS-IV | VIQT+2 | WAIS-IV | VIQT+ | WAIS-IV | VIQT+ | |
| Matrices (MR/MA) | 2 | 17 | 0 | 12 | 16 | 25 |
| Puzzels (FS/PU) | 3 | 18 | 0 | 11 | 17 | 25 |
| Gewichten (GW) | 4 | 16 | 1 | 12 | 18 | 24 |
| PRI1 (WAIS-IV) | 9 | 1 | 1433 | |||
| TIQ (VIQT+) | 51 | 35 | 170+ | |||
tabel 1: vergelijking voor een 30-jarige tussen de WAIS-IV PRI (Pearson, WAIS-IV-NL afname en scoringshandleiding)
en de VIQT+ (SCALIQ, interne analyse tijdens normeringsonderzoek).
1 Voor de WAIS-IV Perceptueel Redeneren Index is de subtest Blokpatronen vervangen door de subtest Gewichten (wat volgens de WAIS-IV afname en scoringshandleiding is toegestaan), om deze voor wat betreft de testinhoud beter te kunnen vergelijken met het TIQ van de VIQT+.
2 Voor de VIQT+ is hier alleen het aantal items genoteerd – nog zonder rekening te houden met het IRT algoritme dat het mogelijk maakt om, op basis van deels goede antwoorden, preciezer te kunnen differentiëren dan met alleen somscores.
3 De ruwe indexscore is bij de WAIS-IV een optelsom van de geschaalde subtestscores behorend bij de betreffende index. De maximale ruwe indexscore voor een bepaalde leeftijdsgroep is dus de optelsom van de maximale geschaalde subtestscores. Aan de hand van de normtabellen is hiervoor de geschaalde indexscore bepaald.
tabel 1: vergelijking voor een 30-jarige tussen de WAIS-IV PRI (Pearson, WAIS-IV-NL afname en scoringshandleiding)
en de VIQT+ (SCALIQ, interne analyse tijdens normeringsonderzoek).
1 Voor de WAIS-IV Perceptueel Redeneren Index is de subtest Blokpatronen vervangen door de subtest Gewichten (wat volgens de WAIS-IV afname en scoringshandleiding is toegestaan), om deze voor wat betreft de testinhoud beter te kunnen vergelijken met het TIQ van de VIQT+.
2 Voor de VIQT+ is hier alleen het aantal items genoteerd – nog zonder rekening te houden met het IRT algoritme dat het mogelijk maakt om, op basis van deels goede antwoorden, preciezer te kunnen differentiëren dan met alleen somscores.
3 De ruwe indexscore is bij de WAIS-IV een optelsom van de geschaalde subtestscores behorend bij de betreffende index. De maximale ruwe indexscore voor een bepaalde leeftijdsgroep is dus de optelsom van de maximale geschaalde subtestscores. Aan de hand van de normtabellen is hiervoor de geschaalde indexscore bepaald.
Lagere betrouwbaarheid aan de randen van het scorebereik
In de technische handleiding van elk instrument wordt de betrouwbaarheid gegeven. Dit is een getal tussen de 0 en de 1: hoe dichter bij 1, hoe betrouwbaarder het instrument. Een meting met een betrouwbaarheid van 0 is nutteloos: je kunt dan net zo goed een muntje opgooien. Metingen met een betrouwbaarheid van 1 bestaan niet: bij elke meting is er sprake van enige meetonzekerheid. Hoe betrouwbaarder een test, hoe kleiner de meetonzekerheid.
Intelligentietesten met een betrouwbaarheid boven de 0.9 worden volgens de COTAN normen gezien als goed betrouwbaar voor het maken van belangrijke beslissingen op individueel niveau. 0.8 is ook nog voldoende betrouwbaar, maar bij een betrouwbaarheid daaronder kan een testuitslag eigenlijk alleen nog maar gebruikt worden voor minder belangrijke beslissingen. Onder de 0.7 is de betrouwbaarheid alleen nog maar geschikt om uitspraken te doen op groepsniveau (zoals bij een grootschalig onderzoek naar de effectiviteit van een bepaalde onderwijsinterventie, waarbij het belangrijk is om te corrigeren voor intelligentie).
De betrouwbaarheid van een intelligentietest die voor het scoren gebruikmaakt van somscores (wat bij vrijwel alle Nederlandse intelligentietesten het geval is) wordt in de handleiding gerapporteerd aan de hand van de betrouwbaarheid in het midden van het meetbereik. Daar is de betrouwbaarheid van alle veelgebruikte intelligentietesten in Nederland zeer hoog: meestal rond de 0.95. Zo’n hoge betrouwbaarheid betekent dat de meetfout (SEM) rond het gemiddelde 3.35 is. De betrouwbaarheid van de test wordt bij het rapporteren van de scores uitgedrukt in een betrouwbaarheidsinterval. Een SEM van 3.35 geeft een betrouwbaarheidsinterval van ongeveer 12 punten rondom de gemeten score: 6 punten omlaag en 6 punten omhoog vanaf de gemeten score.
De meetfout van de geschaalde testscores (zoals de subtestscores of het TIQ) neemt echter toe naarmate iemand verder boven het gemiddelde scoort: wel 2 tot 4 keer hoger richting de randen van het meetbereik van een test [Hunsaker, 2012].
In de tabel hieronder zie je wat dat doet met de meetfout, de betrouwbaarheid en het betrouwbaarheidsinterval van een intelligentietest met een hoge betrouwbaarheid van 0.95 en een meetbereik van IQ 40 tot 160.
| Meetfout (SEM) |
Gecorrigeerde meetfout | Gecorrigeerde betrouwbaarheid | 95% betrouwbaar-heidsinterval | |
| 100 (94-106) | 3.35 | 3.35 | 0.95 | 12 pt |
| 130 (122-135) | 3.35 | 6.70 (2x groter) | 0.80 | 26 pt |
| 145 (137-149) | 3.35 | 10.05 (3x groter) | 0.55 | 39 pt |
| 160 (151-163) | 3.35 | 13.40 (4x groter) | 0.20 | 52 pt |
tabel 2: werkelijke betrouwbaarheid van een intelligentietest met een betrouwbaarheid van 0.95 en een meetbereik van 40-160, die voor het scoren gebruik maakt van klassieke testtheorie (somscores).

tabel 2: werkelijke betrouwbaarheid van een intelligentietest met een betrouwbaarheid van 0.95 en een meetbereik van 40-160, die voor het scoren gebruik maakt van klassieke testtheorie (somscores).
Zoals je in de laatste kolom kunt zien, wordt het 95% betrouwbaarheidsinterval veel breder richting de extremen van het meetbereik. Waar het bij een TIQ van 100 nog 12 punten is (94-106), is dat bij een TIQ van 130 al opgelopen tot 26 punten, en bij een score van 160 zelfs 52 (!) punten.
Omdat er bij herhaalde metingen bovendien sprake is van regressie naar het gemiddelde, ligt het middelpunt van een betrouwbaarheidsinterval altijd wat meer richting het gemiddelde dan de gemeten score zelf (zowel bij zeer hoge als bij zeer lage scores).
Voor een gemeten TIQ van 130 zal het gecorrigeerde betrouwbaarheidsinterval dus 111-137 zijn, in plaats van de 122-135 die veelal gerapporteerd wordt. Voor een TIQ van 145 is het gecorrigeerde betrouwbaarheidsinterval ongeveer 110-148.
We moeten ons afvragen of het wel gerechtvaardigd is om op basis van een score met zo’n lage betrouwbaarheid, en zo’n breed betrouwbaarheidsinterval, te bepalen wie er wel of geen toegang krijgt tot belangrijke onderwijsvoorzieningen (zoals voltijds hoogbegaafden onderwijs). En of je bij een volwassene met een reguliere test goed onderscheid kunt maken tussen ‘bovengemiddeld intelligent’, ‘hoogbegaafd’ of ‘zeer hoogbegaafd’.
Te weinig hoogbegaafden in de normeringssteekproef
Bij een klassieke normering met een aselecte normgroep van 1500 mensen zitten, volgens verwachting, slechts 37 mensen die een score van 130 of hoger behalen. Over alle leeftijdsgroepen heen. Dat vertaalt zich wiskundig gezien in een minder precieze norm aan de randen van het scorebereik van de test: de normfout.
Deze normfout wordt groter naarmate een IQ-score verder van het gemiddelde af ligt (zowel naar onder als naar boven). Er zijn voor iemand met een score aan de rand van het scorebereik simpelweg te weinig mensen in de vergelijkingsgroep om de gegeven antwoorden mee te vergelijken.
De normfout moet eigenlijk ook nog opgeteld worden bij het betrouwbaarheidsinterval, waardoor deze zelfs nog breder wordt dan op basis van alleen de gecorrigeerde meetfout.
Problemen signaleren die er niet zijn
Het argument van veel scholen om voor toelating tot hb-onderwijs toch te kiezen voor een veelgebruikte test als de WISC-V is vaak dat deze meer informatie geeft, omdat hij een breder profiel meet dan de KIQT+. Maar is dit wel terecht?
De betrouwbaarheid van subtest- en indexscores is lager dan die van de TIQ-score. Dit komt doordat een subtestscore op minder opgaven (en dus minder informatie) gebaseerd is dan de TIQ score. En ook voor deze scores geldt dat de betrouwbaarheid aan de bovenkant van het meetbereik lager wordt.
Daarnaast geldt dat de index- en subtestscores weinig predictieve validiteit hebben bovenop de gemeten TIQ-score [De Jong, 2023]. De klinische waarde van een breed gemeten intelligentieprofiel is hierdoor maar klein, en ook over het wel of niet succesvol zijn op school zeggen de aanvullende scores minder dan veel mensen denken.
Sterker nog: soms worden er op basis van een breed intelligentieprofiel problemen gesignaleerd of verwacht die er in de praktijk helemaal niet zijn. Uit een TIQ van 140, met ergens een losse subtestscore van 13 of een losse indexscore van 115, wordt dan de conclusie getrokken dat er sprake is van problemen op dat specifieke vlak. Terwijl zulke scores nog steeds ruim bovengemiddeld zijn.
Verschillen in subtest- en indexscores zijn bovendien heel normaal. Zeker ook bij hoogbegaafden, gezien de mindere betrouwbaarheid van de subtest- en indexscores in combinatie met de teruglopende betrouwbaarheid aan de bovenkant van het scorebereik.
Is het voor toelating tot HB-onderwijs belangrijker om 10 of meer verschillende subtestscores, 5 primaire indexen en 5 aanvullende indexen in een rapport te hebben staan waarvan zowel de betrouwbaarheid als de predictieve validiteit beperkt zijn? Of gaan we voor een zo betrouwbaar mogelijke meting van de algemene intelligentie, en kijken (en luisteren) we daarnaast naar het kind zelf om te beoordelen wat de best passende vorm van onderwijs is?
Wat maakt de KIQT+ en de VIQT+ beter geschikt?
Voor het grootste deel van de bevolking zijn de bestaande testen dus al heel betrouwbaar. Maar net zoals er voor het betrouwbaar kunnen meten van een zeer lage intelligentie ooit een beter geschikte test ontwikkeld is (de RAKIT-2), was er ook voor kinderen en volwassenen aan de bovenkant van de intelligentiecurve iets anders nodig.
Dat is waarom in 2021 de KIQT+ in gebruik is genomen voor vermoedelijk hoogbegaafde kinderen van 5 tot en met 10 jaar, en waarom in 2026 ook de VIQT+ genormeerd wordt (voor kinderen en volwassenen van 10 tot en met 70 jaar).
De KIQT+ en de VIQT+ meten net als de WISC-V en de WAIS-IV de algemene intelligentie, maar doen dat op een manier die beter passend en vooral ook meer betrouwbaar is voor de vermoedelijk hoogbegaafde doelgroep.
De belangrijkste verbeteringen
Hoger instapniveau en minder makkelijke opgaven
De KIQT+ en de VIQT+ hebben allebei een hoger instapniveau dan reguliere intelligentietesten. Er is dus minder risico dat zeer intelligente kinderen/volwassenen afhaken voordat ze zijn aangekomen bij opgaven die passen bij hun denkniveau.
Meer moeilijke opgaven
Er zijn meer opgaven die gebruikt kunnen worden voor het meten van een hoge intelligentie (zoals te zien was in tabel 1 eerder in dit artikel), en de opgaven worden naar het eind van de test ook veel moeilijker. Er kan dus betrouwbaarder worden gemeten aan de bovenkant van de curve (tot een IQ van 170).
Geen tijdsdruk
Zolang iemand op een productieve manier bezig is met een opgave, en er nog concrete stapjes worden gezet in de richting van een oplossing (of deze nu goed of fout is), mag er altijd worden doorgegaan. Dit zorgt voor een ontspannen afname en vermindert ruis door verschillen in hoe mensen omgaan met tijdsdruk.
Normering volgens het DARSIS model
Door gebruik te maken van de bekende structuur van hoe intelligentie zich over leeftijd heen ontwikkelt [Y. Cramer, 2021] is het mogelijk om nauwkeuriger te normeren. Deze manier van normeren staat aan de basis van de KIQT+ en de VIQT+, en heeft het bij de KIQT+ mogelijk gemaakt om gebruik te maken van een initiële normgroep van bijna 800 (vermoedelijk) (hoog)begaafde kinderen, met gemiddeld een (eerder gemeten) IQ van rond de 130. Dit betekent dat er in de normgroep veel meer kinderen met een (zeer) hoog IQ zaten dan in de normgroep van andere intelligentietesten.
Normering aanvullend ondersteund door die van de ZOOV+ en de VOQS
25.000 afnames in a-selecte groepen in het basis- en voortgezet onderwijs, gestratificeerd naar schoolweging (BO) en schoolniveau (VO). In zo’n grote steekproef zitten statistisch gezien ongeveer 600 hoogbegaafden, in plaats van de ongeveer 35 in de normeringssteekproef van de meeste andere intelligentietesten.
IRT in plaats van somscores
Voor het berekenen van de scores wordt niet alleen gekeken naar hoeveel opgaven er goed beantwoord zijn, maar ook naar welke opgaven dat waren.
Bij een fout antwoord wordt er ook gekeken naar of het een slim fout antwoord was, of een minder slim fout antwoord.
De kalibratie van de items (de inschatting van de moeilijkheidsgraad, en de beoordeling welke foute antwoorden slim of minder slim zijn) wordt continu gefinetuned aan de hand van nieuw ingevoerde afnames. Dat zijn er voor de KIQT+ inmiddels meer dan 9.000.
Item Respons Theorie
Eén van deze verbeteringen lichten we graag even verder toe: In de KIQT+ en de VIQT+ wordt voor het scoren, in plaats van Klassieke Test Theorie (KTT), gebruikgemaakt van Item Respons Theorie (IRT). Dat is een wezenlijk andere manier van scoren, waarbij niet alleen gekeken wordt naar het aantal goede antwoorden maar naar het volledige antwoordpatroon.
Welke opgaven zijn goed beantwoord?
Met IRT kijk je niet alleen naar hoeveel opgaven er goed zijn beantwoord, maar ook naar welke opgaven dat waren. Elk antwoord wordt bekeken als onderdeel van het gehele antwoordpatroon.
Bij scoren volgens IRT ga je ervan uit dat iemand die een aantal moeilijke opgaven goed heeft kunnen beantwoorden, de makkelijkere opgaven ook zal kunnen snappen. Dit is eigenlijk hetzelfde als bij een klassieke test met een leeftijdsafhankelijk instapniveau: bij een ouder iemand mag je dan bijvoorbeeld instappen bij opgave 4, en als diegene opgave 4 en 5 allebei goed beantwoordt mag je opgave 1 tot en met 3 ook als goed beantwoord noteren (ook al heb je die niet aangeboden). Bij IRT wordt dat principe door de hele test heen gebruikt, in plaats van alleen bij het bepalen van het instapniveau.
Maakt iemand aan het begin bij de makkelijke opgaven een paar foutjes, maar geeft hij of zij daarna op een rij moeilijke opgaven wel het goede antwoord, dan zal een KTT score alleen het totale aantal goede antwoorden weergeven. De IRT score neemt de moeilijkheid van de opgaven die als laatste goed beantwoord zijn ook mee in de beoordeling.
Als een fout antwoord niet ‘past’ in het patroon omdat de volgende vijf antwoorden weer goed zijn, wordt het herkend als ‘waarschijnlijk een slordigheidsfoutje of een moment van onoplettendheid’ en zal het minder zwaar gewogen worden. Past een fout antwoord wel in het patroon (bijvoorbeeld omdat de vraag ervoor en de vragen erna ook fout beantwoord zijn), dan wordt het volledig meegerekend.
In het voorbeeld hieronder krijgt Bart daarom bijna dezelfde score als Anne.

| ← makkelijke vragen moeilijke vragen → | KTT score |
IRT score |
||||||||||
| 1 | 2 | 3 | 4 | 5 | 6 | 7 | 8 | 9 | 10 | |||
| Anne | √ | √ | √ | √ | √ | √ | √ | X | X | X | 7 | 7 |
| Bart | √ | X | √ | √ | √ | √ | √ | X | X | X | 6 | 6.9 |
| Claartje | √ | √ | √ | √ | √ | √ | √ | √ | √ | √ | 10 | 10+ |
| Dirk | – | – | – | √ | √ | √ | √ | √ | √ | √ | 7 | 10+ |
Heeft iemand alle moeilijke opgaven goed beantwoord, en waren er daarna geen opgaven meer over, dan zal IRT er rekening mee houden dat iemand nog moeilijkere opgaven misschien ook goed zou kunnen beantwoorden. In het voorbeeld hierboven is de score van Claartje daarom geen 10 zoals bij KTT, maar 10+. Dirk heeft op de eerste drie opgaven geen antwoord gegeven (misschien omdat hij twijfelde over het aantal appeltjes in de boom), maar heeft daarna wel alle moeilijke opgaven goed beantwoord. Hij heeft hiermee aangetoond dat hij hetzelfde moeilijke niveau aankan als Claartje, daarom krijgt ook hij de score 10+.
Hoe fout zijn de foute antwoorden precies?
Bij een fout antwoord wordt met IRT ook gekeken naar welk fout antwoord er dan gegeven is, en of dat foute antwoord ‘slim’ is of niet.
Welke foute antwoorden ‘slim’ zijn en welke niet hoeft een psycholoog niet zelf te beoordelen. Bij sommige opgaven zou dat nog wel kunnen, maar bij andere ligt het zo genuanceerd dat het bijna niet mogelijk is dat te beoordelen op basis van alleen de opgave zelf. Het IRT algoritme helpt daar dus bij: het vergelijkt elk fout antwoord met alle antwoordpatronen die in het systeem staan. Wordt een bepaald fout antwoord vooral gegeven door kinderen met een relatief hoge score (die naast dit foute antwoord dus ook veel goede antwoorden geven), dan is het een ‘slim fout’ antwoord. Wordt het vooral gegeven door kinderen met een relatief lage score dan is het juist een ‘niet zo slim fout’ antwoord. Die vergelijking wordt continu gemaakt op basis van alle tot dan toe ingevoerde afnames, en de weging van de foute antwoorden wordt dus steeds preciezer naarmate er meer afnames zijn ingevoerd.

In de opgave van de grafiek hierboven is G (de zwarte lijn) het goede antwoord. Je ziet dat de kans dat een kind op deze vraag het goede antwoord geeft stijgt naarmate de vaardigheidsscore van een kind hoger wordt (de zwarte lijn begint bij 0 en neemt daarna steeds verder toe). Precies zoals je zou verwachten voor een goed antwoord: hoe hoger iemands intelligentie, hoe groter de kans dat hij/zij een vraag goed beantwoordt. Voor de roze lijn (antwoord E, één van de foute antwoorden) geldt het omgekeerde: hoe intelligenter, hoe kleiner de kans dat dit antwoord gegeven wordt. Dit lijkt dus een heel voor de hand liggend antwoord (want het wordt relatief vaak gegeven), maar alleen als je totaal niet doorhebt hoe de opgave werkt. De gele lijn (antwoord F) is een fout antwoord dat vooral gegeven wordt door mensen met een relatief hoge vaardigheidsscore. Dit is dus een ‘slim’ fout antwoord. Je zou met andere woorden kunnen zeggen dat dit antwoord ‘deels goed’ is. De andere vragen zitten er een beetje tussenin, waarbij hogere pieken een duidelijker signaal geven en dus zwaarder worden meegewogen.
Dat meewegen van foute antwoorden gebeurt beide kanten op: slimme foute antwoorden kunnen de ruwe score iets verhogen. Minder slimme foute antwoorden kunnen de ruwe score juist iets verlagen. Het effect daarvan per opgave is overigens maar klein: het goede antwoord levert altijd een stuk meer punten op dan een fout antwoord, ook al is dat foute antwoord een ‘slimme fout’ (en andersom zal ook een eventuele aftrek maar klein zijn). Het is een soort ‘finetunen’ van de ruwe score.
Dit finetunen maakt het mogelijk om ook te differentiëren ‘tussen de goede antwoorden in’. Zo creëer je met 10 opgaven in de praktijk veel meer dan 10 verschillende ‘meetpunten’. Bij de KIQT+ en de VIQT+ betekent dit dat je met hetzelfde aantal opgaven veel preciezer kunt meten dan bij een somscore het geval zou zijn.
Kijkend naar tabel 1 eerder in dit artikel heeft de VIQT+ per subtest voor de geschaalde subtestscores van 18 tot 25 bij een 30-jarige nog 12 opgaven beschikbaar, en door het finetunen met IRT worden dat per subtest meer dan twee keer zoveel meetpunten. Minimaal 24 meetpunten dus, voor een geschaald scorebereik van 8 punten. Dat is een enorm verschil met de WAIS-IV, die bij dezelfde leeftijd voor de geschaalde subtestscores van 14 tot 18 (een geschaald scorebereik van 5 punten) nog maar twee tot vier meetpunten (opgaven) overheeft.
Dit is waarom het mogelijk is om met de KIQT+ en de VIQT+ veel nauwkeuriger te meten in het hoogbegaafde en zeer hoogbegaafde scorebereik.
Hoe zit het met de betrouwbaarheid bij hogere IQ-scores?
Een bijkomend voordeel van het gebruik van een IRT algoritme, is dat de betrouwbaarheid van een test over het volledige leeftijds- en scorebereik heel precies kan worden berekend. Van de KIQT+ weten we daarom dat de betrouwbaarheid over een heel groot deel van het bereik minimaal 0.95 of zelfs hoger is.
| IQ 105 | IQ 115 | IQ 130 | IQ 145 | IQ 160 | IQ 170 | |
| 5 jaar | 0.94 | 0.94 | 0.95 | 0.96 | 0.97 | 0.97 |
| 6 jaar | 0.94 | 0.95 | 0.96 | 0.97 | 0.97 | 0.97 |
| 7 jaar | 0.95 | 0.96 | 0.97 | 0.97 | 0.97 | 0.96 |
| 8 jaar | 0.95 | 0.96 | 0.97 | 0.97 | 0.96 | 0.92 |
| 9 jaar | 0.96 | 0.97 | 0.97 | 0.97 | 0.93 | 0.86 |
| 10 jaar | 0.96 | 0.97 | 0.97 | 0.96 | 0.90 | 0.78 |
Hoewel de VIQT+ op moment van schrijven nog niet volledig genormeerd is, kan op basis van alle afnames tot nu toe al wel een voorlopige betrouwbaarheid berekend worden. En ook die is (met nog ongeveer 400 afnames te gaan) al over vrijwel het volledige meetbereik hoger dan 0.95.
Hoe zit het met de betrouwbaarheid bij hogere IQ-scores?
Een bijkomend voordeel van het gebruik van een IRT algoritme, is dat de betrouwbaarheid van een test over het volledige leeftijds- en scorebereik heel precies kan worden berekend. Van de KIQT+ weten we daarom dat de betrouwbaarheid over een heel groot deel van het bereik minimaal 0.95 of zelfs hoger is.

Hoewel de VIQT+ op moment van schrijven nog niet volledig genormeerd is, kan op basis van alle afnames tot nu toe al wel een voorlopige betrouwbaarheid berekend worden. En ook die is (met nog ongeveer 400 afnames te gaan) al over vrijwel het volledige meetbereik hoger dan 0.95.
Intelligentieonderzoek op een goede manier inzetten
Aanbevelingen voor diagnostici
Maak vooraf expliciet: wat is de vraag?
“Is er sprake van (zeer) hoge begaafdheid en/of “is er sprake van (zeer) hoge intelligentie? “Dit vraagt om maximale precisie aan de bovenkant. “Hoe functioneert iemand cognitief in brede zin?” is een andere vraag. Leg vast welke beslissing(en) aan de uitkomst gekoppeld worden (toelating, voorzieningen, behandelroute, loopbaanbesluit).
Voorkom dat tijdsdruk ‘intelligentie’ gaat meten.
Zeker bij vermoedelijk hoogbegaafden en 2e-profielen (ASS/ADHD/angst/trauma) kan timing en korte afbreekcriteria scores omlaag trekken. NAGC wijst er bij de WISC-V expliciet op dat tijdsdruk is toegenomen en dat dit intelligentie kan onderschatten.
Behandel FSIQ/TIQ en profielen met discipline, niet met enthousiasme.
Profielanalyse (sterktes/zwaktes) is verleidelijk, maar bij de WISC-V laten validiteitsanalyses zien dat “profielen” beperkt houvast bieden; index-/subtestscores voegen vaak weinig toe boven g/FSIQ voor interpretatie.
Praktisch: benadruk onzekerheid, baseer conclusies op convergerende aanwijzingen (observatie, anamnese, onderwijs-/werkdata), en wees terughoudend met klinische labels op basis van één lage(re) indexscore die nog steeds bovengemiddeld is.
Rapporteer altijd betrouwbaarheidsintervallen en bespreek ze begrijpelijk.
Als de uitkomst consequenties heeft, hoort de onzekerheidsmarge in het gesprek centraal te staan. Vermijd harde conclusies op één punt-score (“IQ 144 dus niet”). Werk dus met bandbreedtes en leg uit dat precisie aan de randen doorgaans afneemt (dit principe wordt in de literatuur breed benoemd; exacte factor-2-tot-4 verschilt per test/scorebereik).
Wees expliciet over wat je níét kunt hardmaken.
Bij vermoedelijk zeer hoge intelligentie geldt: “met deze test kunnen we onderbouwen dat het hoog is, maar het exacte niveau (bijv. 145 vs 155) is minder zeker” — tenzij je een instrument gebruikt dat aantoonbaar beter differentieert aan de bovenkant én waarvan je de technische onderbouwing kunt laten zien.
Neem ‘fit’ en follow-up net zo serieus als de score.
Een score zonder vertaling naar onderwijs/werk/zelfinzicht is een dood eind. Eindig met concrete adviezen: welk type instructie, tempo, autonomie, prikkelregulatie, peers, executieve ondersteuning past hierbij?
Aanbevelingen voor scholen / toelatingscommissies
Stop met “één getal, één poort”.
Gebruik geen harde afkapwaarden zonder bandbreedte. Als je een IQ-criterium hanteert, werk dan met confidence intervals en met aanvullende gegevens (leerlingwerk, didactische voorsprong, observaties, gesprek met leerling/ouders).
Wees extra voorzichtig met verwerkingssnelheid en werkgeheugen als ‘zwakte’.
Hoogbegaafde leerlingen kunnen relatief lager scoren op verwerkingssnelheid; NAGC waarschuwt dat een overmatige nadruk daarop signalering/een betrouwbare meting kan hinderen. Een “lagere” (maar nog gemiddelde) score betekent niet automatisch een probleem dat onderwijs blokkeert.
Kies instrumenten passend bij de beslissing die je neemt.
Als het gaat om het onderscheid binnen de bovenkant (hoog vs zeer hoog), is een instrument nodig dat daar voldoende kan differentiëren. Als je dat niet hebt: wees eerlijk over de onzekerheid en maak het besluit breder dan alleen de testscore.
Organiseer follow-up als standaard, niet als gunst.
Screening of testen is pas zinvol als er daarna structureel iets verandert: compacten, verrijken, versnellen, plus begeleiding op sociaal, emotioneel en/of executief vlak waar nodig.
Aanbevelingen voor mensen die zichzelf (of hun kinderen) herkennen in hoogbegaafdheid
Bepaal je doel vóór je test.
Wil je erkenning/zelfinzicht, toegang tot voorzieningen, of een cognitief profiel voor begeleiding? Je doel bepaalt welke test(aanpak) passend is en hoe je de uitslag moet lezen.
Bereid praktisch voor, niet inhoudelijk.
Oefenen “voor IQ” heeft weinig zin. Wél zinvol? Uitgerust, gegeten, prikkelarm, en spanning reduceren (kennismaking, weten hoe de dag loopt). Dit vergroot de kans dat de meting jouw functioneren weerspiegelt, niet je stressniveau.
Vraag om uitleg in gewone taal mét bandbreedte.
Laat degene die de test afneemt niet alleen een score geven, maar ook aangeven: wat betekent dit in leren/werken, waar zit je energie-lek, wat is je ideale context, en welke aanpassingen helpen morgen al?
Wat kun je zelf doen om je goed voor te bereiden op een intelligentieonderzoek?
Flink studeren of oefenen voor een intelligentietest is niet nodig (en heeft ook geen zin). Alle soorten opgaven zullen tijdens de afname worden uitgelegd aan de hand van enkele voorbeeldopgaven. Pas wanneer je die voorbeeldopgaven goed begrijpt, zal de tester doorgaan met de echte opgaven.
Als jouw kind (of jijzelf) het spannend vindt om in een vreemde omgeving te zijn en/of met een onbekende in gesprek te gaan, kan het helpen om van tevoren vast een keer kennis te maken. Soms helpt het ook al om op de website van de praktijk die het intelligentieonderzoek uitvoert even op te zoeken wie de tester is, wat de werkwijze is tijdens een onderzoek, of hoe het er binnen uitziet.
Zorg dat je goed uitgerust op de testdag verschijnt, dat je voldoende gegeten hebt, en dat je wat snacks en iets te drinken bij je hebt. Nadenken wordt echt moeilijker als je moe bent of honger hebt.
En onthoud vooral: het doel van intelligentieonderzoek is niet om een zo hoog mogelijke score te behalen, maar om een zo betrouwbaar mogelijk beeld te verkrijgen van jouw functioneren (of dat van je kind). Een goede psycholoog of orthopedagoog gaat daarvoor op een zo ontspannen mogelijke manier samen met jou op zoek naar de grens van wat je nog net lukt, en wat echt te moeilijk voor je is.
Bronnen
- Cramer, Y. (2021). Distribution across age of raw and scaled intelligence scores: The DARSIS model [Preprint]. OSF. https://doi.org/10.31234/osf.io/en82j
- de Jong, P. F. (2023). The validity of WISC-V profiles of strengths and weaknesses. Journal of Psychoeducational Assessment, 41, 363–379. https://doi.org/10.1177/07342829221150868
- Grondhuis, S. N., Lecavalier, L., Arnold, L. E., Handen, B. L., Scahill, L., McDougle, C. J., & Aman, M. G. (2018). Differences in verbal and nonverbal IQ test scores in children with autism spectrum disorder. Research in Autism Spectrum Disorders, 49, 47–55. https://doi.org/10.1016/j.rasd.2018.02.001
- Hunsaker, S. L. (Ed.). (2012). Identification: The theory and practice of identifying students for gifted and talented education services. Creative Learning Press.
- Na, S. D., & Burns, T. G. (2016). Wechsler Intelligence Scale for Children–V: Test review. Applied Neuropsychology: Child, 5(2), 156–160. https://doi.org/10.1080/21622965.2015.1015337
- Nader, A.-M., Courchesne, V., Dawson, M., & Soulières, I. (2016). Does WISC-IV underestimate the intelligence of autistic children? Journal of Autism and Developmental Disorders, 46(5), 1582–1589. https://doi.org/10.1007/s10803-014-2270-z
- National Association for Gifted Children. (2018, August 1). Use of the WISC-V for gifted and twice exceptional identification (Position statement).
- Silverman, L. K. (2009). The measurement of giftedness. In L. V. Shavinina (Ed.), International handbook on giftedness (pp. 947–970). Springer. https://doi.org/10.1007/978-1-4020-6162-2_48
- Silverman, L. K. (2018). Assessment of giftedness. In S. I. Pfeiffer (Ed.), Handbook of giftedness in children: Psychoeducational theory, research, and best practices (2nd ed., pp. 183–207). Springer. https://doi.org/10.1007/978-3-319-77004-8_12
- Wechsler, D. (2012). WAIS-IV-NL: Nederlandstalige bewerking. Afname- en scoringshandleiding. Pearson Assessment & Information.
